
41분
ChatGPT Prompt Engineering for Developers
앤드류 응 교수님의 ChatGPT 프롬프트 엔지니어링 강의
실습코드: https://github.com/JHSeo-git/chatgpt-prompt-eng.git
LLM의 동작 방식을 설명하고, 신속한 엔지니어링을 위한 몇 가지 사례를 소개하며, 다양한 작업을 위해 애플리케이션에서 LLM API를 활용할 수 있는 법을 안내합니다.
다음 몇 가지 카테고리에서 LLM API를 어떻게 활용하는지를 강의에서 배울 수 있었습니다:
- Summarizing(예: 사용자 리뷰 요약)
- Inferring(예: 감정 분류, 주제 추출)
- Transforming text(예: 번역, 맞춤법, 문법 수정)
- Expanding(예: 이메일 자동 작성)
그리고 효과적인 프롬프트를 작성하기 위한 2가지 핵심 원칙과 좋은 프롬프트를 체계적으로 설계하는 방법, 커스텀 ChatBot을 만드는 방법 또한 안내해줍니다.
총 1시간 가량으로 간결하게 설명해주고 있으며, 핵심적인 내용을 다양한 예제와 함께 설명해주고 있어서 좀 더 쉽게 이해할 수 있었습니다.
모든 예제 코드는 강좌에서 영상과 함께 제공됩니다. 강의를 들으시면서 직접 실습해보시는 것을 추천드립니다.
사용된 파이썬 예제 코드는 강의마다 제공되지만 제가 실습해본 코드에서도 확인할 수 있습니다.
1장: Introduction
LLM을 크게 2가지 타입으로 나누면 Base LLM과 Instruction Tuned LLM이 있습니다.
- Base LLM: 학습된 데이터에 기반하여 다음 단어를 예측합니다.
- Instruction Tuned LLM: 사용자가 지정한 프롬프트에 따라 다음 단어를 예측합니다.

Base LLM은 인터넷 등 대량의 소스 데이터로 훈련됩니다. 다음에 나올 가능성이 가장 높은 단어가 무엇인지 알아냅니다. 예를 들어 "유니콘이 있었습니다."라는 글을 입력했다면 "그것은 마법의 숲에 살고 있습니다."와 같이 다음에 올 단어를 예측하여 대답합니다. 그러나 "프랑스 수도가 무엇인가요?" 라고 입력했다면 "프랑스 인구는 얼마인가요?" 또는 "프랑스에서 가장 큰 것은 무엇인가요?" 와 같은 인터넷 기사 제목을 예측하여 대답할 수도 있습니다.
이와는 대조적으로 LLM에 지침을 주어 LLM을 조정할 수도 있습니다. 지침에 맞게 조정된 LLM은 지침에 맞게 대답할 수 있습니다. 그래서 만약 "프랑스 수도가 무엇인가요?" 라고 물었을 때 "프랑스의 수도는 파리입니다."와 같은 출력을 할 가능성이 높습니다.
Instruction Tuned LLM은 일반적으로 훈련되는 방식은 다음과 같습니다. 방대한 양의 텍스트 데이터로 훈련된 Base LLM으로 시작합니다. 그리고 입력과 출력으로 fine tune(미세 조정)을 위해 추가로 훈련합니다.
지침과 입출력 조정 후에 종종 RLHF(Reinforcement Learning with Human Feedback)이라는 강화학습을 사용하여 LLM을 더욱 세분화하기도 합니다. 이런 모델의 경우 정직하며 무해하도록 훈련되었기 때문에 독성 출력과 같은 문제가 있는 텍스트를 출력할 가능성이 적습니다.
실제 사용 사례에는 많은 부분이 Instruction Tuned LLM이 더 적합할 수 있습니다. 그래서 오늘날 대부분의 실제 애플리케이션의 경우 Instruction Tuned LLM을 사용하기를 권장합니다.
LLM에 다음 질문을 하고 답변을 받는다고 생각해봅시다. "앨런 튜링에 대한 글을 써주세요." 라고 물었을 때 그의 과학적 업적에 초점을 맞추기를 원하나요?, 아니면 그의 개인적인 삶이나 역사에서 그의 역할 또는 다른 것에 대해 원하나요?
또한 텍스트의 톤, 어조를 어떻게 취해야 할까요? 전문 저널리스트 어조여야 하나요? 아니면 친구에게 편하게 말하듯이 써야 하나요?
이러한 작업을 성공적으로 수행하기 위해서 프롬프트에 명확하고 구체적으로 말하는 방법, 즉 프롬프트의 중요한 원칙을 다음 강의에서 소개하겠습니다.
2장: Guidelines
이 강의에서 사용되는 예제 언어는 Python입니다. Jupyter Notebook 예제를 강의와 함께 제공하고 있으며, 강의 내용도 예제를 중심으로 설명하고 있습니다.
몇 가지 프롬프트 원칙과 전술을 간략하게 설명하겠습니다.
- 첫 번째 원칙은 명확하고 구체적인 지침을 작성하는 것입니다.
- 두 번째 원칙은 생각할 시간을 주는 것입니다.
첫 번째 원칙: 명확하고 구체적인 지침
모델이 수행할 작업을 최대한 명확하고 가능한 한 구체적으로 지침을 제공해야 합니다.
이렇게 하면 모델을 원하는 출력으로 유도하고 관련성이 없어가 잘못된 응답을 얻을 가능성을 줄일 수 있습니다. 명확한 프롬프트 작성과 짧은 프롬프트 작성을 혼동하지 마세요. 긴 프롬프트가 실제로 모델에 더 많은 명확성과 컨텍스트를 제공하기 때문에 실제로 더 상세하고 관련성 있는 결과물을 얻을 수 있습니다.
명확하고 구체적인 지침을 작성하는데 도움이 되는 첫 번째 전략은 구분 기호(delimiters)를 사용하는 것입니다.
- Triple quotes:
""" - Triple backticks:
``` - Triple dashes:
--- - Angle brackets:
< > - XML tags:
<tag> </tag>
text = f"""
You should express what you want a model to do by \
providing instructions that are as clear and \
specific as you can possibly make them. \
This will guide the model towards the desired output, \
and reduce the chances of receiving irrelevant \
or incorrect responses. Don't confuse writing a \
clear prompt with writing a short prompt. \
In many cases, longer prompts provide more clarity \
and context for the model, which can lead to \
more detailed and relevant outputs.
"""
prompt = f"""
Summarize the text delimited by triple backticks \
into a single sentence.
```{text}```
"""
response = get_completion(prompt)
모델에게 이것이 별도의 섹션이라는 것을 구분하게 할 수 있습니다. 특정 텍스트를 나머지 프롬프트와 구분하는 명확한 구분자를 사용하여 프롬프트를 작성합니다.
이렇게 함으로써 프롬프트 주입(prompt injection)을 피할 수 있습니다. (프롬프트와 상충되거나 예시같은 것을 프롬프트와 별개로 지시하기 위해 사용합니다.)
이러한 구분 기호를 통해 모델은 프롬프트의 일부가 아닌 별도의 섹션으로 간주합니다. 모델이 프롬프트의 일부로 간주하는 것을 피하려면 구분 기호를 사용하는 것이 좋습니다.
두 번째 전략은 구조화된 출력(structured output)을 요청하는 것입니다.
모델 출력을 더 쉽게 분석하려면, HTML이나 JSON과 같은 구조화된 출력을 요청하는 것이 도움이 될 수 있습니다.
prompt = f"""
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""
response = get_completion(prompt)
print(response)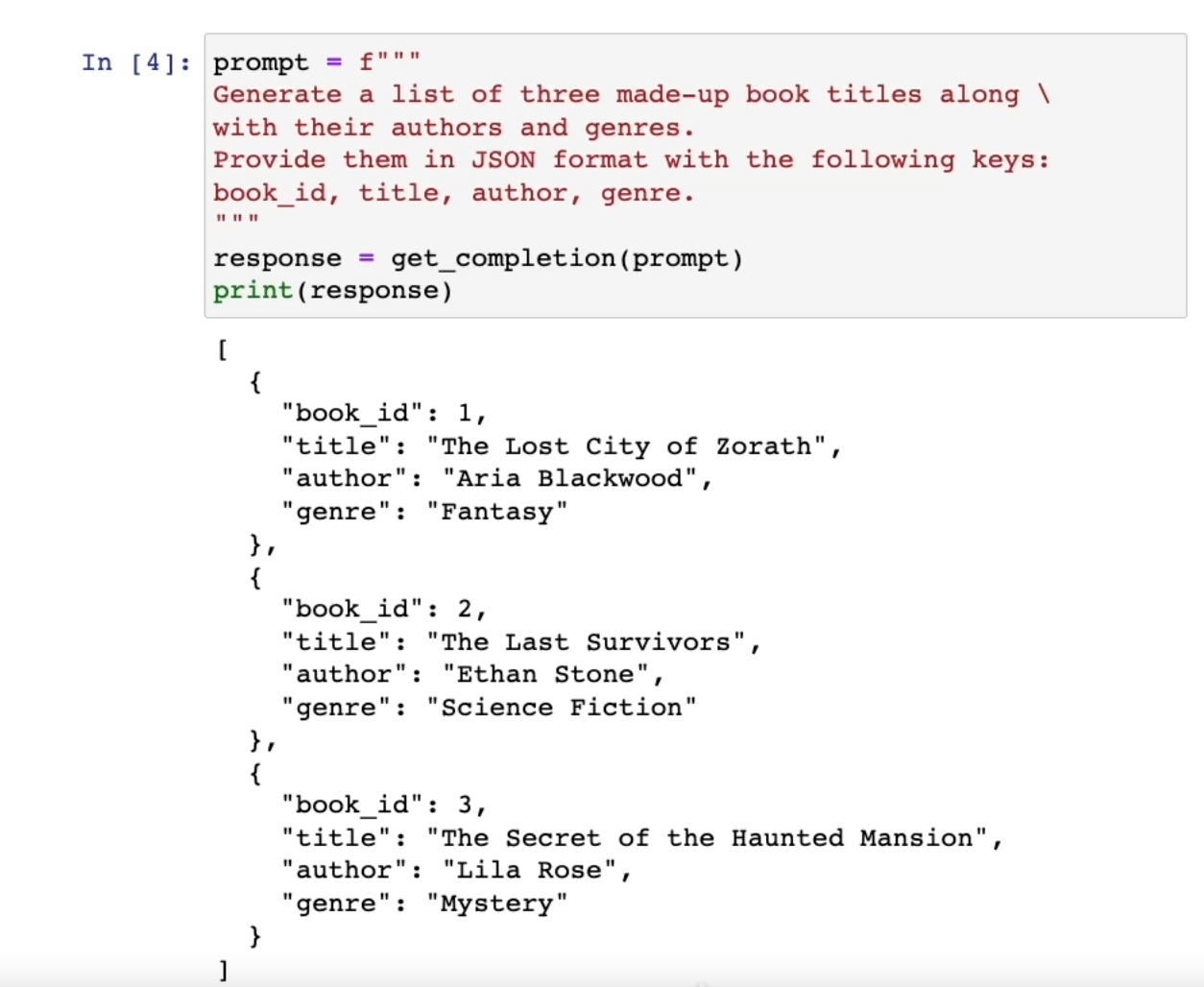
이를 통해서 파이썬(또는 다른 언어에서) 쉽게 파싱하고 처리할 수 있습니다.
세 번째 전략은 모델에 조건이 충족되는지 확인하도록 요청하는 것입니다.
모델에 만족해야되는 가정을 지시한 다음에, 이러한 가정을 먼저 확인 후 충족되지 않는다면 이를 표시하고 작업 시도를 중단하도록 할 수 있습니다.
text_1 = f"""
Making a cup of tea is easy! First, you need to get some \
water boiling. While that's happening, \
grab a cup and put a tea bag in it. Once the water is \
hot enough, just pour it over the tea bag. \
Let it sit for a bit so the tea can steep. After a \
few minutes, take out the tea bag. If you \
like, you can add some sugar or milk to taste. \
And that's it! You've got yourself a delicious \
cup of tea to enjoy.
"""
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text_1}\"\"\"
"""
response = get_completion(prompt)
print("Completion for Text 1:")
print(response)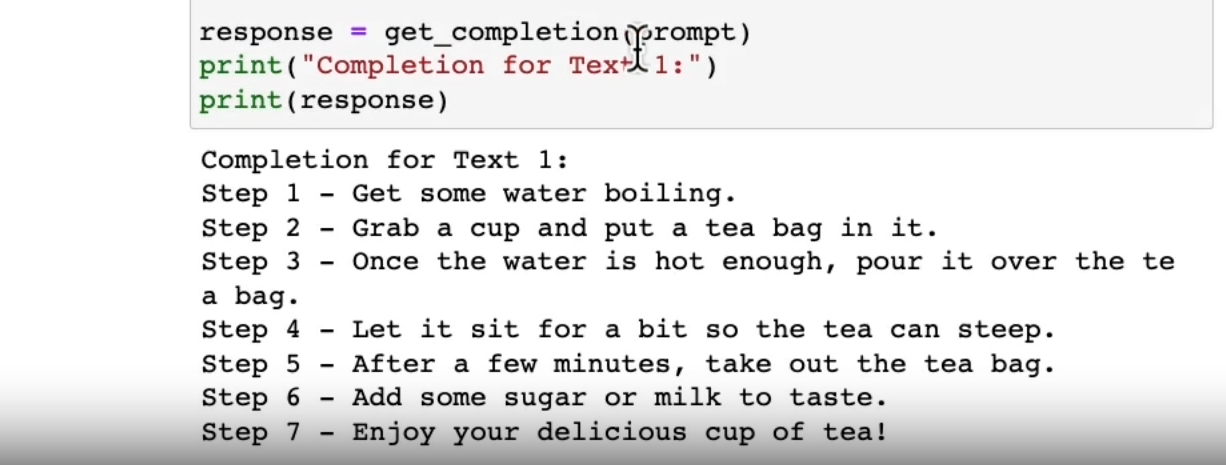
text_2 = f"""
The sun is shining brightly today, and the birds are \
singing. It's a beautiful day to go for a \
walk in the park. The flowers are blooming, and the \
trees are swaying gently in the breeze. People \
are out and about, enjoying the lovely weather. \
Some are having picnics, while others are playing \
games or simply relaxing on the grass. It's a \
perfect day to spend time outdoors and appreciate the \
beauty of nature.
"""
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text_2}\"\"\"
"""
response = get_completion(prompt)
print("Completion for Text 2:")
print(response)
이를 통해서 잠재적인 엣지 케이스와 예상지 못한 오류나 결과를 피하기 위해 모델이 어떻게 처리해야 하는지 명확하게 지시할 수 있습니다.
마지막 전략은 few-shot 프롬프트 입니다. 이는 수행하려는 작업에 대한 성공적인 예시를 제공하여 모델이 작업을 수행하는 방법을 알려주는 것입니다.
prompt = f"""
Your task is to answer in a consistent style.
<child>: Teach me about patience.
<grandparent>: The river that carves the deepest \
valley flows from a modest spring; the \
grandest symphony originates from a single note; \
the most intricate tapestry begins with a solitary thread.
<child>: Teach me about resilience.
"""
response = get_completion(prompt)
print(response)위 대화에서 조부모님은 일종의 은유적이고 친절하게 답변하고 있습니다. 모델에게 일관된 어조로 대답하라고 지시하였으니 다음과 같은 어조로 대답합니다.

위 4가지가 명확하고 구체적인 지침을 제공하는 전략입니다.
- 프롬프트 주입을 피하도록 구분 기호를 사용합니다.
- 구조화된 출력을 요청합니다.
- 모델에 조건이 충족되는지 확인하도록 요청합니다.
- few-shot 프롬프트를 사용합니다.
두 번째 원칙: 생각할 시간 주기
두 번째 원칙은 모델에 생각할 시간을 주는 것입니다.
모델이 추론 오류를 범하는 경우 또는 잘못된 결론에 도달하는 경우 모델이 최종 답변을 제공하기 전에 일련의 관련 추론을 요청하도록 쿼리를 재구성해보세요.
또한 모델에 너무 복잡한 작업을 요청 (예: 단기간에 수행하기 어려운 작업, 너무 적은 단어로만 이루어진 요청)을 하면 모델이 잘못된 추측을 할 수 있다는 것입니다. 이는 사람에게도 일어날 수 있는 일입니다. 만약 누군가에게 복잡한 수학을 풀라고 하면 실수할 가능성이 높습니다.
따라서 이러한 상황에서는 모델에게 더 오래 생각하도록 지시할 수 있습니다. 또는 더 많은 계산 작업을 수행하도록 지시할 수 있습니다.
두 번째 원칙에도 몇 가지 전략을 소개할텐데, 첫 번째 전략은 작업을 완료하는데 필요한 단계를 지정하는 것입니다.
text = f"""
In a charming village, siblings Jack and Jill set out on \
a quest to fetch water from a hilltop \
well. As they climbed, singing joyfully, misfortune \
struck—Jack tripped on a stone and tumbled \
down the hill, with Jill following suit. \
Though slightly battered, the pair returned home to \
comforting embraces. Despite the mishap, \
their adventurous spirits remained undimmed, and they \
continued exploring with delight.
"""
# example 1
prompt_1 = f"""
Perform the following actions:
1 - Summarize the following text delimited by triple \
backticks with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the following \
keys: french_summary, num_names.
Separate your answers with line breaks.
Text:
```{text}```
"""
response = get_completion(prompt_1)
print("Completion for prompt 1:")
print(response)
위 예시에서는 모델에게 4가지 작업을 수행하도록 지시하고 있습니다. 첫 번째 작업은 요약을 하라는 것이고, 두 번째 작업은 요약을 번역하라는 것입니다. 세 번째 작업은 번역된 요약에서 각 이름을 나열하라는 것이고, 네 번째 작업은 JSON 객체를 출력하라는 것입니다.
이 예제는 이름, 제목이 프랑스어로 되어 있습니다. 만약 그대로 전달한다면 잘못된 이해를 할 수 있습니다. 어떨 때는 이름이 표시될 수도 있고, 때로는 프랑스어로된 제목이 표시될 수도 있기 때문입니다.
따라서 더 명시적인 포맷으로 지시하도록 합니다.
prompt_2 = f"""
Your task is to perform the following actions:
1 - Summarize the following text delimited by
<> with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the
following keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in Italian summary>
Output JSON: <json with summary and num_names>
Text: <{text}>
"""
response = get_completion(prompt_2)
print("\nCompletion for prompt 2:")
print(response)
위는 더 명시적인 포맷으로 결과를 요청하는 예시입니다.
첫 번째 지시 요청에 답변으로 프랑스어로 답변이 나왔기 때문에 명시적인 포맷으로 지시를 요청하여 더 이해하기 쉽게 만들었습니다.
여기서는 < > 기호를 사용했지만 어떤 구분 기호를 선택하든 상관없습니다.
다음 전략은 결론에 도달하기 전에 모델 스스로 해결책을 찾도록 유도하는 것입니다. 모델 스스로 추론하도록 지시하면 더 나은 결과를 얻을 수 있습니다.
모델이 정답인지 아닌지를 말하기 전 해결할 시간을 주는 것 에 대해 얘기했던 것과 같은 아이디어입니다.
prompt = f"""
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need \
help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
"""
response = get_completion(prompt)
print(response)이 문제에서는 모델에게 학생의 답이 맞는지 아닌지 판단하도록 요청하고 있습니다. 따라서 수학 문제가 먼저 있고, 그 다음에 학생의 답이 있습니다. 실제로 학생의 답은 잘못된 것입니다.
이를 실행하면 모델은 학생의 답이 맞다고 말합니다.

계산되어야 정확한 유지보수 비용은 100,000 + 100x이 아니라 100,000 + 10x 입니다.
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 이 라인만 본다면 맞습니다.
그래서 모델은 학생의 답이 맞다고 판단합니다.
이를 해결하기 위해 모델에게 자체적으로 해결책을 찾도록 지시하고 그런 다음 학생의 답과 비교하도록 지시하겠습니다.
prompt = f"""
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
```
question here
```
Student's solution:
```
student's solution here
```
Actual solution:
```
steps to work out the solution and your solution here
```
Is the student's solution the same as actual solution \
just calculated:
```
yes or no
```
Student grade:
```
correct or incorrect
```
Question:
```
I'm building a solar power installation and I need help \
working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations \
as a function of the number of square feet.
```
Student's solution:
```
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
```
Actual solution:
"""
response = get_completion(prompt)
print(response)
모델이 문제에 대한 자신만의 해결책을 작성합니다. 그런 다음 자신의 답과 학생의 답을 비교합니다. 학생의 답이 올바른지 결정하도록 하지 마세요. 모델이 명확하게 직접 문제를 풀도록 하세요.
위 2가지가 모델에게 생각할 시간을 주는 전략입니다.
- 작업을 완료하는데 필요한 단계를 지정합니다.
- 결론에 도달하기 전에 모델 스스로 해결책을 찾도록 유도합니다.
모델 한계: Hallucination(환각)
대규모 언어 모델을 사용하는 애플리케이션을 개발할 때 모델 제한 사항을 염두에 두는 것이 정말 중요합니다.
모델이 학습 과정에서 방대한 양의 데이터에 노출되어도 정보를 완벽하게 암기하지 못하기 때문에
지식의 경계를 잘 모릅니다.
즉, 모호한 주제에 대한 질문에 대답하려고 할 때 그럴듯하게 들리지만 실제로는 사실이 아닌 답변을 생성할 수 있습니다.
이러한 조작된 답변을 Hallucination(환각)이라고 부릅니다.
환각을 일으키는 사례의 예는 다음과 같습니다.
prompt = f"""
Tell me about AeroGlide UltraSlim Smart Toothbrush by Boie
"""
response = get_completion(prompt)
print(response)Boie는 실제 있는 회사 이지만 AeroGlide UltraSlim Smart Toothbrush는 실제로는 존재하지 않는 제품입니다.

모델이 가상의 제품에 대해 매우 현실적으로 설명하고 있습니다. 이것이 위험한 이유는 실제로 꽤나 현실적으로 들리기 때문입니다. 그리고 이것이 LLM에 알려진 약점입니다.
이를 해결하기 위해 많은 노력을 하고 있습니다. 가령 환각을 줄이기 위해 모델에게 먼저 텍스트에서 관련 인용문을 찾도록 요청하는 것입니다. 그 인용문을 사용하여 질문에 답하도록 요청하고 그 답을 다시 소스 문서로 추적하도록 하여 환각을 줄이는 방법입니다.
다음은 iterative 프롬프트 개발 프로세스에 대해서 알아보겠습니다.
3장: Iterative
프롬프트를 반복적으로 개선할 수 있는 좋은 프로세스가 있다면 원하는 작업에 적합한 무언가를 얻을 수 있을 것입니다.
머신러닝 모델을 학습시킬 때 처음에 제대로 작동하는 경우는 거의 없나는 말을 들어보셨을 겁니다. 처음부터 제대로 작동하는 경우는 거의 없습니다.
또한 첫 번째 프롬프트가 잘 작동하는지 여부는 그렇게 중요하지 않습니다. 가장 중요한 것은 자신에게 맞는 프롬프트에 도달하는 과정입니다.
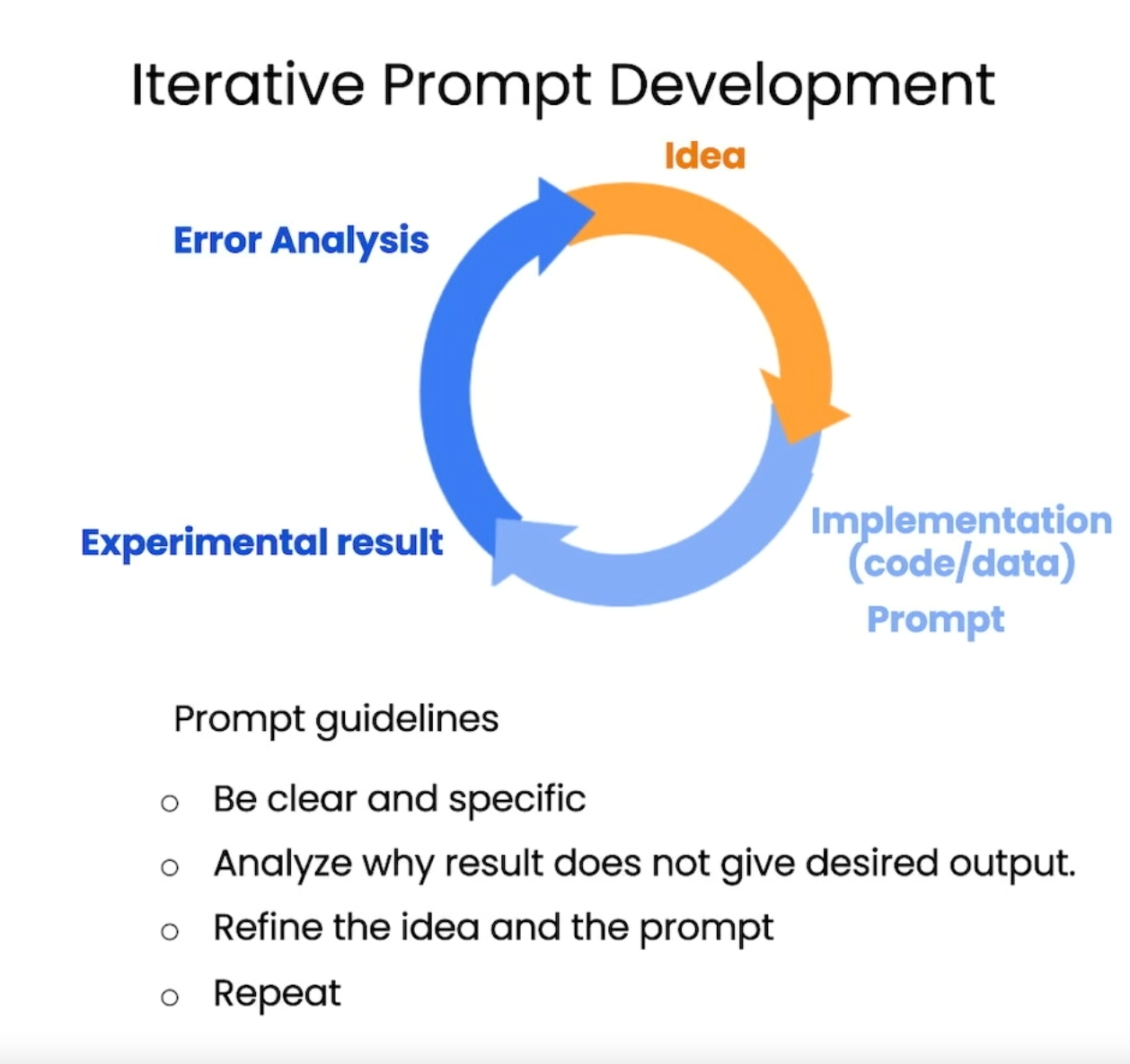
프롬프트를 작성할 때 위와 같은 프로세스를 따르는 것이 중요합니다. 이 루프를 여러 번 돌면서 애플리케이션에 적합한 프롬프트가 나올 때까지 여러 번 반복할 수도 있습니다. 이것이 개인적으로 "30가지 완벽한 프롬프트"와 같은 인터넷 기사에 많은 관심을 기울이지 않은 이유이기도 합니다. 완벽한 프롬프트는 없다고 생각하기 때문입니다. 더 중요한 것은 특별한 애플리케이션을 위해 좋은 프롬프트를 개발하는 프로세스를 가지는 것이 더 중요합니다.
그럼 이제 예제와 함께 어떻게 프롬프트를 반복적으로 개선, 개발하는 지에 대해 알아보겠습니다.
예제: 의자 Fact Sheet를 이용한 프롬프트 개발
fact_sheet_chair = """
OVERVIEW
- Part of a beautiful family of mid-century inspired office furniture,
including filing cabinets, desks, bookcases, meeting tables, and more.
- Several options of shell color and base finishes.
- Available with plastic back and front upholstery (SWC-100)
or full upholstery (SWC-110) in 10 fabric and 6 leather options.
- Base finish options are: stainless steel, matte black,
gloss white, or chrome.
- Chair is available with or without armrests.
- Suitable for home or business settings.
- Qualified for contract use.
CONSTRUCTION
- 5-wheel plastic coated aluminum base.
- Pneumatic chair adjust for easy raise/lower action.
DIMENSIONS
- WIDTH 53 CM | 20.87”
- DEPTH 51 CM | 20.08”
- HEIGHT 80 CM | 31.50”
- SEAT HEIGHT 44 CM | 17.32”
- SEAT DEPTH 41 CM | 16.14”
OPTIONS
- Soft or hard-floor caster options.
- Two choices of seat foam densities:
medium (1.8 lb/ft3) or high (2.8 lb/ft3)
- Armless or 8 position PU armrests
MATERIALS
SHELL BASE GLIDER
- Cast Aluminum with modified nylon PA6/PA66 coating.
- Shell thickness: 10 mm.
SEAT
- HD36 foam
COUNTRY OF ORIGIN
- Italy
"""예제 코드는 의자에 대한 정보를 담고 있습니다. 해당 의자는 중세시대에 영감을 받았고, 의자의 치수, 옵션, 재료 등을 설명하고 있습니다.
위 정보를 가지고 마케팅 팀이 온라인 쇼핑몰에 올릴 상품 설명을 작성하려고 합니다.
prompt = f"""
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
triple backticks.
Technical specifications: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)LLM에 첫 번째 프롬프트를 작성해보았습니다.

설명이 잘 작성된 것 같고, 기술적인 정보에 기반하여 설명해달라는 요청도 잘 반영된 것 같습니다. 하지만 이 내용은 상품 설명하기에는 너무 깁니다. 조금 더 짧으면 좋을 것 같습니다.
Issue 1: 너무 긴 텍스트
너무 긴 텍스트가 마음에 들지 않아 프롬프트를 더 명확히 하고 원하는 길이에 대한 지침을 제공하기 위해
Use at most 50 words. 문장을 추가하여 최대 50 단어만 사용하도록 요청하는 프롬프트로 수정해보겠습니다.
prompt = f"""
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
triple backticks.
Use at most 50 words.
Technical specifications: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)
내용도 잘 들어가 있고 단어도 52개로 되어있어서 나쁘지 않습니다. LLM은 매우 정확한 단어 수에 대한 지침을 따르는 데는 그다시 능숙하지 않지만 이 정도면 충분합니다. 가끔 60단어, 65단어 등의 단어로 출력되는 경우도 있지만 어느 정도는 괜찮습니다.
만약 이 웹사이트가 소매점이 아니라 도매점이라면, 프롬프트를 조금 더 수정해야 할 것입니다. 이 경우 프롬프트를 수정하여 기술적 세부 정보를 더 정확하게 표시하면 좋을 것 같습니다.
Issue 2: 원치않은 세부정보에 초점을 맞추는 경우
prompt = f"""
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
triple backticks.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
Use at most 50 words.
Technical specifications: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)조금 더 명확한 지침을 제공하기 위해 프롬프트를 수정해보았습니다. 이제는 상품 설명이 소매를 위한게 아닌 도매를 위한 것이라고 명시하고 있습니다. 그리고 좀 더 기술적인 세부 정보에 초점을 맞추도록 요청하고 있습니다.

나쁘지 않습니다.
프롬프트를 변경하면 원하는 특성에 더 초점을 맞추도록 할 수 있습니다. 가령 설명 끝 부분에 ID를 추가하고 싶다면 다음과 같이 프롬프트를 수정할 수 있습니다.
prompt = f"""
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
triple backticks.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
At the end of the description, include every 7-character
Product ID in the technical specification.
Use at most 50 words.
Technical specifications: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)
이런 방식이 개발자가 겪게 될 반복적인 프롬프트 개발의 짧은 예시입니다.
이와 같이 베스트 프랙틱스를 염두에 두고 명확하고 구체적으로 설명하며, 필요한 경우 모델에 생각할 시간을 줍니다. 따라서 어떤 일이 일어나는지 확인한 다음, 필요한 결과에 점점 더 가까워질 수 있도록 프롬프트를 반복적으로 다듬어 가는 것이 좋습니다.
다양한 프로그램에서 사용되는 성공적인 프롬프트의 대부분은 이와 같은 반복적인 과정을 거쳐 완성되었습니다.
좀 더 나아가자면 더 복잡한 프롬프트를 이용해 더 구체적인 작업을 수행할 수도 있습니다.
Issue 3: 설명글에 제품 치수 표가 필요합니다.
설명글에 제품 치수를 제공하는 표를 포함시킨 다음, 모든 형식을 HTML로 지정하도록 해보겠습니다.
prompt = f"""
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
triple backticks.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
At the end of the description, include every 7-character
Product ID in the technical specification.
After the description, include a table that gives the
product's dimensions. The table should have two columns.
In the first column include the name of the dimension.
In the second column include the measurements in inches only.
Give the table the title 'Product Dimensions'.
Format everything as HTML that can be used in a website.
Place the description in a <div> element.
Technical specifications: ```{fact_sheet_chair}```
"""
response = get_completion(prompt)
print(response)
HTML결과로 설명글이 결과로 나타나지고, 또한 제품 치수 표도 추가되었습니다.
이를 통해 프롬프트 개발은 반복적인 과정이라는 점을 이해하셨으면 좋겠습니다. 무언가를 시도하고, 원하는 것을 정확히 충족시키는지 확인한 다음 지침을 명확히하는 방법에 대해 생각하거나 경우에 따라 생각할 공간을 더 많이 제공하여 원하는 결과에 더 가까워지는 방법에 대해 생각하세요.
효과적인 프롬프트 엔지니어가 되기 위한 핵심은 완벽한 프롬프트를 아는 것이 아니라 애플리케이션에 효과적인 프롬프트를 개발할 수 있는 좋은 프로세스를 갖추는 것이라고 생각합니다.
대부분 애플리케이션을 처음 개발할 때는 한 가지 예제만 가지고 개발하는 경우가 많지만, 좀 더 성숙한 애플리케이션의 경우에는 수십개의 예제를 가지고 프롬프트를 테스트하여 여러 결과에서 평균 또는 최악의 경우 성능을 확인하는 것이 좋습니다.
다음은 LLM을 가장 일반적으로 사용하는 방법 중에 하나인 텍스트 요약에 대해서 알아보겠습니다.
4장: Summarizing
오늘날에는 텍스트가 너무 많아서 모든 텍스트를 읽을 충분한 시간을 가진 사람은 거의 없습니다. 그래서 LLM 중 가장 흥미로운 활용 사례 중 하나는 텍스트를 요약하는데 사용하는 것입니다.
기사를 요약하기 항상 이 작업을 수행하는데, 이전보다 훨씬 더 많은 기사의 내용을 쉽게 읽을 수 있습니다.
이제 코드를 보고 직접 텍스트를 요약하는데 어떻게 사용할 수 있는지 알아보겠습니다.
예제: 제품 리뷰 요약
제품 리뷰를 요약하는 작업을 실행 예제로 사용하겠습니다.
prod_review = """
Got this panda plush toy for my daughter's birthday, \
who loves it and takes it everywhere. It's soft and \
super cute, and its face has a friendly look. It's \
a bit small for what I paid though. I think there \
might be other options that are bigger for the \
same price. It arrived a day earlier than expected, \
so I got to play with it myself before I gave it \
to her.
"""이커머스 웹사이트에서 리뷰의 양이 많은 경우, 긴 리뷰를 요약하는 도구를 사용하면 모든 고객의 더 많은 리뷰를 매우 빠르게 살펴볼 수 있습니다.
단어/문장/글자 제한과 함께 요약하기
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site.
Summarize the review below, delimited by triple
backticks, in at most 30 words.
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
나쁘지 않고 꽤 좋은 요약입니다.
이전 강의에서도 보셨듯이 글자 수나 문장 수를 조절하여 요약의 길이에 영향을 줄 수도 있습니다.
요약을 작성할 때 배송 부서에 피드백을 제공하려는 경우 같이 요약에 대해 매우 구체적인 목적을 염두에 두고 있을 경우 프롬프트를 수정하여 비즈니스 특정 그룹에 더 적합한 요약을 생성할 수도 있습니다.
배송에 초점을 맞추어 요약하기
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site to give feedback to the \
Shipping deparmtment.
Summarize the review below, delimited by triple
backticks, in at most 30 words, and focusing on any aspects \
that mention shipping and delivery of the product.
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
요약 내용이 "Soft and cute panda"로 시작하는 대신 "예상보다 하루 일찍 도착했다는 사실"에 초점을 맞추고 있습니다. 그리고 다른 세부 정보도 계속 표시됩니다.
또 다른 예로 배송 부서에 피드백을 제공하려는 대신 가격 책정 부서에 피드백을 제공하려고 한다고 가정해보겠습니다.
가격에 초점을 맞추어 요약하기
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site to give feedback to the \
pricing deparmtment, responsible for determining the \
price of the product.
Summarize the review below, delimited by triple
backticks, in at most 30 words, and focusing on any aspects \
that are relevant to the price and perceived value.
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
프롬프트에 가격과 인식된 가치에 관련하여 어떤 측면이든 초점을 맞추라고 지시했기 때문에 그에 따라 요약이 생성되었습니다.
이 경우 요약된 내용이 "사이즈에 비해 가격이 비쌀 수 있다"에 초점을 맞추고 있습니다.
그러나 항상 요약된 정보에 원하는 정보만을 포함하고 있는 것은 아닙니다. 따라서 반대로 원하는 방식에 따라 내용을 추출하도록 요청할 수도 있습니다.
"요약" 대신 "추출"하기
prompt = f"""
Your task is to extract relevant information from \
a product review from an ecommerce site to give \
feedback to the Shipping department.
From the review below, delimited by triple quotes \
extract the information relevant to shipping and \
delivery. Limit to 30 words.
Review: ```{prod_review}```
"""
response = get_completion(prompt)
print(response)배송 부서에 피드백을 제공하기 위해 관련 정보를 추출하도록 프롬프트를 작성해보았습니다.

그 결과 다른 정보 없이 "제품이 하루 일찍 도착했다"는 정보만 표시됩니다. 배송 부서에서 알고 싶은 것은 위와 같이 배송에 무슨 일이 있었는지뿐일 수도 있습니다.
마지막으로 이커머스 업무에서 이 기능을 활용하여 여러 리뷰를 읽기 쉽게 요약하는 방법에 대한 예를 살펴보겠습니다.
여러 상품 리뷰 요약하기
다음은 여러 상품 리뷰들입니다.
review_1 = prod_review
# review for a standing lamp
review_2 = """
Needed a nice lamp for my bedroom, and this one \
had additional storage and not too high of a price \
point. Got it fast - arrived in 2 days. The string \
to the lamp broke during the transit and the company \
happily sent over a new one. Came within a few days \
as well. It was easy to put together. Then I had a \
missing part, so I contacted their support and they \
very quickly got me the missing piece! Seems to me \
to be a great company that cares about their customers \
and products.
"""
# review for an electric toothbrush
review_3 = """
My dental hygienist recommended an electric toothbrush, \
which is why I got this. The battery life seems to be \
pretty impressive so far. After initial charging and \
leaving the charger plugged in for the first week to \
condition the battery, I've unplugged the charger and \
been using it for twice daily brushing for the last \
3 weeks all on the same charge. But the toothbrush head \
is too small. I’ve seen baby toothbrushes bigger than \
this one. I wish the head was bigger with different \
length bristles to get between teeth better because \
this one doesn’t. Overall if you can get this one \
around the $50 mark, it's a good deal. The manufactuer's \
replacements heads are pretty expensive, but you can \
get generic ones that're more reasonably priced. This \
toothbrush makes me feel like I've been to the dentist \
every day. My teeth feel sparkly clean!
"""
# review for a blender
review_4 = """
So, they still had the 17 piece system on seasonal \
sale for around $49 in the month of November, about \
half off, but for some reason (call it price gouging) \
around the second week of December the prices all went \
up to about anywhere from between $70-$89 for the same \
system. And the 11 piece system went up around $10 or \
so in price also from the earlier sale price of $29. \
So it looks okay, but if you look at the base, the part \
where the blade locks into place doesn’t look as good \
as in previous editions from a few years ago, but I \
plan to be very gentle with it (example, I crush \
very hard items like beans, ice, rice, etc. in the \
blender first then pulverize them in the serving size \
I want in the blender then switch to the whipping \
blade for a finer flour, and use the cross cutting blade \
first when making smoothies, then use the flat blade \
if I need them finer/less pulpy). Special tip when making \
smoothies, finely cut and freeze the fruits and \
vegetables (if using spinach-lightly stew soften the \
spinach then freeze until ready for use-and if making \
sorbet, use a small to medium sized food processor) \
that you plan to use that way you can avoid adding so \
much ice if at all-when making your smoothie. \
After about a year, the motor was making a funny noise. \
I called customer service but the warranty expired \
already, so I had to buy another one. FYI: The overall \
quality has gone done in these types of products, so \
they are kind of counting on brand recognition and \
consumer loyalty to maintain sales. Got it in about \
two days.
"""
reviews = [review_1, review_2, review_3, review_4]4개 리뷰 뿐이지만 텍스트가 많습니다. 이 모든 것을 자세히 읽지 않고도 리뷰어들이 쓴 내용을 알고 싶다면 어떻게 해야 할까요?
for i in range(len(reviews)):
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site.
Summarize the review below, delimited by triple \
backticks in at most 20 words.
Review: ```{reviews[i]}```
"""
response = get_completion(prompt)
print(i, response, "\n")리뷰에 대해 for loop을 사용하여 각각 요약을 생성합니다.
프롬프트로는 최대 20단어로 요약하도록 요청하였습니다.

수백 개의 리뷰가 있는 웹사이트라면 이 기능을 사용하여 대시보드를 만들어 엄청난 수의 리뷰를 요약하여 쉽게 읽을 수 있습니다. 간단한 요약을 생성하여 자신이나 다른 사람의 리뷰를 훨씬 더 빠르게 탐색할 수도 있습니다. 또는 고객이 원할 경우 클릭 시 긴 원본 리뷰를 보여주는 것도 좋은 방법입니다.
텍스트가 많은 애플리케이션이 있다면 이와 같은 프롬프트를 사용하여 요약하고 사람들이 텍스트의 내용을 빠르게 파악하고 원하는 겨우 더 자세히 살펴볼 수 있도록 하는 방법을 상상해 보셨으면 좋겠습니다.
다음은 텍스트를 사용하여 추론하는 LLM의 또 다른 기능에 대해 살펴보겠습니다. 예를 들어, 제품 리뷰가 있는데 어떤 제품 리뷰가 긍정적인지 부정적인지 매우 빠르게 파악하고 싶은 경우 사용할 수 있는 기능입니다.
5장: Inferring
이번 강의는 추론에 관한 내용입니다.
LLM의 정말 좋은 점 중 하나는 기존에 복잡하고 많은 프로세스를 필요로 했던 작업을 프롬프트를 작성하기만 하면 바로 결과를 생성할 수 있다는 것입니다. 다양한 모델을 훈련하고 배포할 필요가 없습니다.
이번 강의도 마찬가지로 예제를 통해 어떻게 작동하는지 살펴보겠습니다.
예제: 램프 리뷰
다음은 램프 제품에 대한 리뷰입니다.
lamp_review = """
Needed a nice lamp for my bedroom, and this one had \
additional storage and not too high of a price point. \
Got it fast. The string to our lamp broke during the \
transit and the company happily sent over a new one. \
Came within a few days as well. It was easy to put \
together. I had a missing part, so I contacted their \
support and they very quickly got me the missing piece! \
Lumina seems to me to be a great company that cares \
about their customers and products!!
"""이 리뷰를 사용해 감정을 분류하는 프롬프트를 작성해 보겠습니다.
감정 (positive/negative)
prompt = f"""
What is the sentiment of the following product review,
which is delimited with triple backticks?
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
이 리뷰의 감정이 긍정적이라고 나와 있습니다. 실제로 꽤 맞는 것 같습니다. 램프가 완벽하지는 않지만 이 고객은 꽤 만족하는 것 같습니다.
결과를 더 쉽게 이해하기 위해 더 간결한 답변을 요청할 수도 있습니다.
prompt = f"""
What is the sentiment of the following product review,
which is delimited with triple backticks?
Give your answer as a single word, either "positive" \
or "negative".
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
"긍정" 또는 "부정" 중 한 단어로 답변을 출력하도록 요청하여 또 다른 무언가를 할 수도 있습니다.
감정 유형 식별
이번에는 해당 리뷰에서 어떤 감정 유형이 있는지 식별하도록 요청해 보겠습니다.
prompt = f"""
Identify a list of emotions that the writer of the \
following review is expressing. Include no more than \
five items in the list. Format your answer as a list of \
lower-case words separated by commas.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
위 결과는 5개 감정 유형이 나열되어 있습니다. LLM은 텍스트에서 특정 내용을 추출하는데 매우 능숙합니다. 위 예시처럼 고객이 특정 제품에 대해 어떻게 생각하는지 이해하는데 유용할 수 있습니다.
분노 표출 식별
고객 지원 부서에서는 특정 사용자가 제품에 대해 분노를 표출하는지 여부를 파악하는 것이 중요합니다. 이를 위해 다음과 같은 프롬프트를 작성할 수 있습니다.
prompt = f"""
Is the writer of the following review expressing anger?\
The review is delimited with triple backticks. \
Give your answer as either yes or no.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
만약 누군가가 정말로 분노를 표출하고 있다면, 빨리 파악하여 대응할 수 있습니다. 위 리뷰에 대해서는 화를 내고 있지 않다고 나와 있습니다.
우리는 지도 학습으로 단 몇 분만에 이 모든 분류기를 만들 수 있습니다.
이 시스템으로 할 수 있는 일을 몇 가지 더 보여드리겠습니다.
고객 리뷰로부터 제품과 회사명 추출하기
prompt = f"""
Identify the following items from the review text:
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks. \
Format your response as a JSON object with \
"Item" and "Brand" as the keys.
If the information isn't present, use "unknown" \
as the value.
Make your response as short as possible.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)이번엔 리뷰에서 더 많은 정보를 추출해보겠습니다. 정보 추출은 자연어 처리의 일부입니다.

위 결과는 리뷰에서 제품 이름과 회사 이름을 추출한 것입니다.
대량의 리뷰를 수집하여 상품 생산자, 리뷰의 감정 유형, 특정 제조업체에 대한 긍저적 또는 부정적 감정에 대해 트렌드를 파악하는데 유용할 수 있습니다.
또한 위 모든 것을 한 번에 수행하는 것도 가능합니다.
prompt = f"""
Identify the following items from the review text:
- Sentiment (positive or negative)
- Is the reviewer expressing anger? (true or false)
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks. \
Format your response as a JSON object with \
"Sentiment", "Anger", "Item" and "Brand" as the keys.
If the information isn't present, use "unknown" \
as the value.
Make your response as short as possible.
Format the Anger value as a boolean.
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)지금까지 살펴본 예제는 감정을 인식하는 프롬프트를 작성하는 방법을 보았습니다.
예제: 기사 주제 추론하기
다음 예제는 정부 기관 직원들이 자신이 근무하는 기관에 대해 어떻게 생각하는지에 대한 가상의 신문 기사입니다. 이 기사에 따르면 NASA 직원들은 자신들이 근무하는 기관에 대해 매우 만족한다고 합니다.
story = """
In a recent survey conducted by the government,
public sector employees were asked to rate their level
of satisfaction with the department they work at.
The results revealed that NASA was the most popular
department with a satisfaction rating of 95%.
One NASA employee, John Smith, commented on the findings,
stating, "I'm not surprised that NASA came out on top.
It's a great place to work with amazing people and
incredible opportunities. I'm proud to be a part of
such an innovative organization."
The results were also welcomed by NASA's management team,
with Director Tom Johnson stating, "We are thrilled to
hear that our employees are satisfied with their work at NASA.
We have a talented and dedicated team who work tirelessly
to achieve our goals, and it's fantastic to see that their
hard work is paying off."
The survey also revealed that the
Social Security Administration had the lowest satisfaction
rating, with only 45% of employees indicating they were
satisfied with their job. The government has pledged to
address the concerns raised by employees in the survey and
work towards improving job satisfaction across all departments.
"""5개 주제 추론하기
위 기사에서 5개 주제를 추론하도록 프롬프트를 작성해보겠습니다.
prompt = f"""
Determine five topics that are being discussed in the \
following text, which is delimited by triple backticks.
Make each item one or two words long.
Format your response as a list of items separated by commas.
Text sample: '''{story}'''
"""
response = get_completion(prompt)
print(response)
추론한 결과 이 글은 정부 기관 설문 조사, 직업 만족도, NASA 등 전반적으로 꽤 만족스럽게 추출하였습니다.
반대로 이 글에 대해 먼저 주제 리스트를 작성하고, 그 주제들이 이 글에 어떻게 나타나는지 확인할 수도 있습니다.
prompt = f"""
Determine whether each item in the following list of \
topics is a topic in the text below, which
is delimited with triple backticks.
Give your answer as list with 0 or 1 for each topic.\
List of topics: {", ".join(topic_list)}
Text sample: '''{story}'''
"""
response = get_completion(prompt)
print(response)
가령 특정 주제의 기사 내용을 추적한다고 가정했을 경우 위와 같은 형태로도 추론할 수 있습니다.
이를 머신러닝에서는 zero-shot 학습 알고리즘이라고 합니다.
학습을 위해 전혀 새로운 데이터를 사용하지 않고, 기존에 학습된 모델을 사용하여 새로운 데이터를 분류하는 방법입니다.
특정 주제에 대한 기사 알림 받기
topic_dict = {i.split(': ')[0]: int(i.split(': ')[1]) for i in response.split(sep='\n')}
if topic_dict['nasa'] == 1:
print("ALERT: New NASA story!")ALERT: New NASA story!위 프롬프트는 예시를 위해서 작성하여서 그다지 강력하지 않습니다. 프로덕션 시스템으로 넘어가면 LLM 결과 출력의 경우 일관성이 없을 수 있기 때문에 JSON 형식과 같은 일관성있는 형태로 출력하도록 변경하는 것이 좋습니다.
"추론"은 여기까지입니다. 단 몇 분만에 위와 같은 작업을 수행할 수 있었습니다.
이전에는 이런 모델을 위해서는 숙련된 머신 러닝 개발자가 며칠 또는 심지어 몆 주가 걸렸습니다. 이제는 프롬프트를 사용하여 머신러닝을 처음 접하는 사람들도 매우 복잡한 자연어 처리 작업을 빠르게 구축하고 추론을 할 수 있게 되었습니다.
다음 강의에서는 텍스트를 번역하는 것, 포맷을 변경하는 것과 같은 텍스트 Transforming에 대해서 살펴보겠습니다.
6장: Transforming
LLM은 입력을 다른 형식으로 변환하는데 매우 능숙합니다. 텍스트를 다른 언어로 변역하거나 맞춤법, 문법 교정을 도와주는데 탁월합니다.
또는 HTML 형식으로 변환하거나 JSON 출력과 같은 형식 변환도 가능합니다.
정규 표현식 때문에 고통스러운 경우가 많은데 이제 LLM과 몇 가지 프롬프트만 있으면 훨씬 더 간단하게 구현할 수 있습니다.
이번 강의도 마찬가지로 예제를 이용해 알아보겠습니다.
다른 언어로 번역하기
LLM은 많은 텍스트를 통해서 학습되었습니다. 그 중 많은 부분이 인터넷에서 수집한 데이터이기 때문에 다양한 언어로 작성된 텍스트가 많습니다. 덕분에 LLM은 다른 언어로 번역하는데 매우 능숙합니다.
이 기능을 사용하는 방법에 대한 몇 가지 예를 살펴보겠습니다.
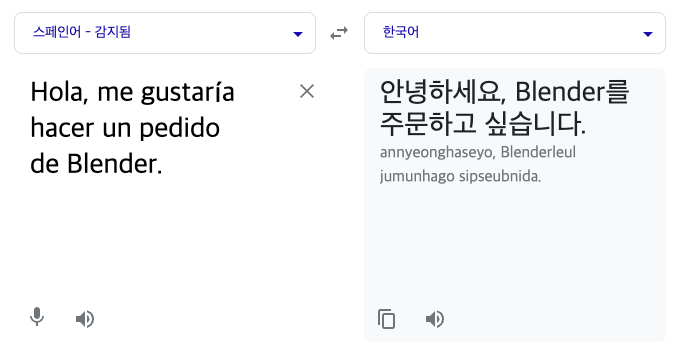
prompt = f"""
Translate the following English text to Spanish: \
```안녕하세요, 블렌더를 주문하고 싶습니다.```
"""
response = get_completion(prompt)
print(response)"안녕하세요, 블렌더를 주문하고 싶습니다."라는 의미의 스페인어로 번역을 요청하였습니다.

스페인어를 잘 몰라 구글번역기를 돌려보니 잘 번역된 것 같습니다.
다음은 프롬프트에 이 텍스트가 어떤 언어인지 맞춰보는 예제입니다.
prompt = f"""
이게 어떤 언어인지 알려주세요:
```Combien coûte le lampadaire?```
"""
response = get_completion(prompt)
print(response)
모델이 이는 프랑스어임을 식별했습니다.
또는 한 번에 여러 언어로 번역할 수도 있습니다.
prompt = f"""
다음 텍스트를 프랑스어 및 스페인어, 해적어로 번역하세요: \
```I want to order a basketball```
"""
response = get_completion(prompt)
print(response)
일부 언어의 경우 상대방의 관계에 따라 번역이 달라질 수 있습니다. 그리고 이를 몯레에 설명하여 그에 따라 번역을 요청할 수 있습니다.
prompt = f"""
공식과 비공식 형식으로 다음 텍스트를 한국어로 번역하십시오.: \
'Would you like to order a pillow?'
"""
response = get_completion(prompt)
print(response)
공식적인 경우는 상급자나 또는 전문적인 상황에 있는 사람과 대화하는 경우입니다. 이때는 공식적인 어조를 사용하고 비공식적인 어조는 친구나 가족과 대화하는 경우입니다.
범용 번역기
다음 예제는 좀 더 범용적으로 번역할 수 있도록 프롬프트를 작성해보기 위한 예제입니다.
다국적 전자 상거래 회사를 담당하고 있다고 가정해보겠습니다. 사용자와는 다양한 언어로 IT 문제에 관해 대화해야 할 것입니다.
먼저 다양한 언어로 된 사용자 메시지 목록을 예시로 사용해보겠습니다.
user_messages = [
"La performance du système est plus lente que d'habitude.", # 시스템 성능이 평소보다 느립니다.
"Mi monitor tiene píxeles que no se iluminan.", # 내 모니터에는 불이 켜지지 않는 픽셀이 있습니다.
"Il mio mouse non funziona", # 내 마우스가 작동하지 않습니다.
"Mój klawisz Ctrl jest zepsuty", # 내 Ctrl 키가 고장 났어요
"我的屏幕在闪烁" # 내 화면이 깜빡입니다.
]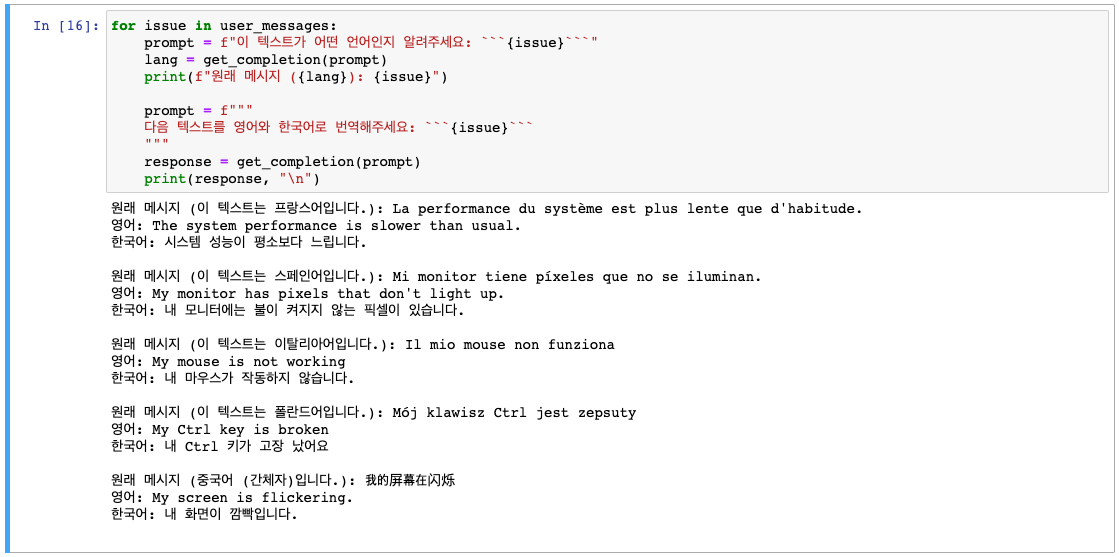
우리는 단 몇 분만에 범용적으로 사용할 수 있는 번역기를 만들었습니다.
한 단어로만 응답하도록 요청할 수도 있고 JSON 형식으로 요청할 수도 있습니다. 전체 문장을 요청하지 않는 것이 좋습니다. 저번 강의 때도 말했지만 출력의 경우 일관성이 없을 수 있기 때문에 JSON 형식과 같은 일관성있는 형태로 출력하도록 변경하는 것이 좋습니다.
어조 변환하기
다음으로 살펴볼 것은 어조 변환입니다. 여러분들도 알다싶이 글을 쓰는 어조는 상대방에 따라 달라질 수 있습니다. 동료나 교수님에게 이메일을 쓸 때와 남동생에게 문자를 보내는 방식은 분명히 다를 것입니다.
이를 위해 다음과 같은 프롬프트를 작성해보겠습니다.
prompt = f"""
Translate the following from slang to a business letter:
'Dude, This is Joe, check out this spec on this standing lamp.'
"""
response = get_completion(prompt)
print(response)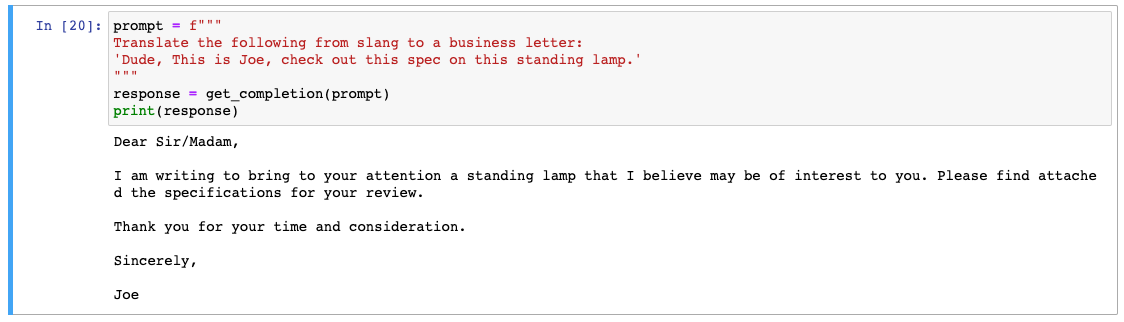
슬랭으로 된 문장을 비니지스 서신으로 변환해달라고 요청하였는데 잘 변환된 것 같습니다.
포맷 변경
다음으로 살펴볼 것은 포맷 변경입니다.
ChatGPT는 JSON과 같은 형식을 HTML, XML, 마크다운 등 다양한 형식 간 변경에 매우 능숙합니다.
data_json = { "resturant employees" :[
{"name":"Shyam", "email":"shyamjaiswal@gmail.com"},
{"name":"Bob", "email":"bob32@gmail.com"},
{"name":"Jai", "email":"jai87@gmail.com"}
]}
prompt = f"""
Translate the following python dictionary from JSON to an HTML \
table with column headers and title: {data_json}
"""
response = get_completion(prompt)
print(response)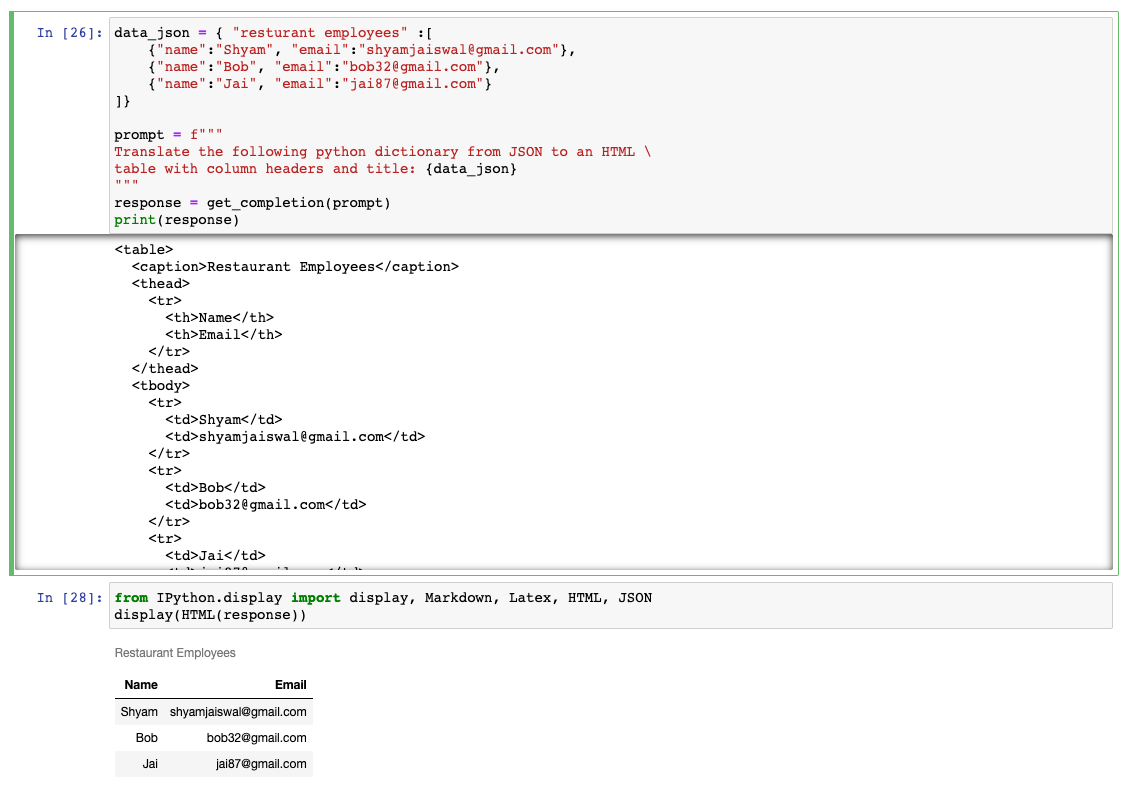
레스토랑 근무자의 이름과 이메일을 JSON 형식으로 작성하였고 이를 HTML 형식으로 변환하라고 요청하였습니다. 테이블의 제목과 열 헤더를 포함하여 HTML 형식으로 변환해달라는 요청도 정확하게 수행하였습니다.
맞춤법 검사
맞춤법 검사는 ChatGPT에서 자주 사용됩니다. 이 작업을 강력히 추천하는데 여러 언어로 작업하는 경우에도 LLM은 잘 수행해내기에 특히 유용합니다.
text = [
"The girl with the black and white puppies have a ball.", # The girl has a ball.
"Yolanda has her notebook.", # ok
"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms
"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms
"Your going to need you’re notebook.", # Homonyms
"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms
"This phrase is to cherck chatGPT for speling abilitty" # spelling
]
for t in text:
prompt = f"""Proofread and correct the following text
and rewrite the corrected version. If you don't find
and errors, just say "No errors found". Don't use
any punctuation around the text:
```{t}```"""
response = get_completion(prompt)
print(response)모델에게 위 문장들을 맞춤법 검사(proofread)해 달라고 요청합니다.

교정된 문장을 출력해주었습니다. 글을 게시하기 전에 맞춤법 검사를 요청하면 오타나 문법 오류에 대해서 더욱 자신감을 가질 수 있을 것입니다.
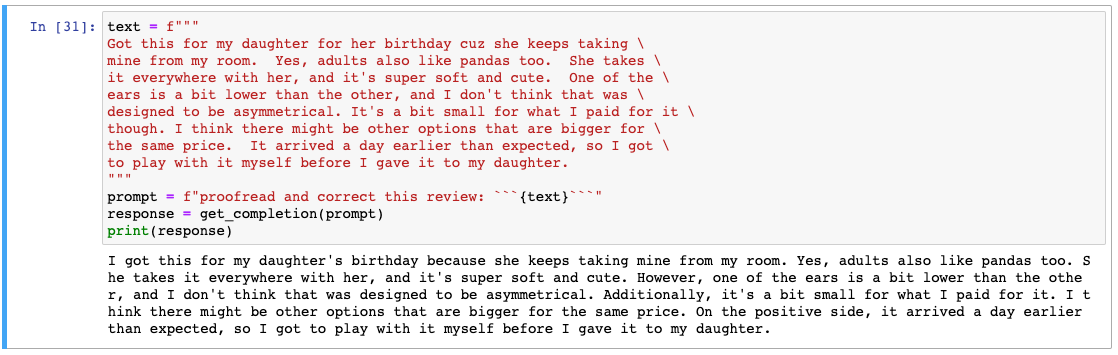
text = f"""
Got this for my daughter for her birthday cuz she keeps taking \
mine from my room. Yes, adults also like pandas too. She takes \
it everywhere with her, and it's super soft and cute. One of the \
ears is a bit lower than the other, and I don't think that was \
designed to be asymmetrical. It's a bit small for what I paid for it \
though. I think there might be other options that are bigger for \
the same price. It arrived a day earlier than expected, so I got \
to play with it myself before I gave it to my daughter.
"""
prompt = f"proofread and correct this review: ```{text}```"
response = get_completion(prompt)
print(response)팬더 인형에 대한 리뷰입니다. 마찬가지로 맞춤법 검사와 교정을 요청하였습니다.
python 라이브러리 redlines를 이용하여 원본과 변경 후의 텍스트의 변경점을 확인해보았습니다.

우리가 사용한 프롬프트는 리뷰를 교정하고 수정할 수도 있지만 좀 더 극적인 변경, 어조 변경 등 다양한 변화를 줄 수 있습니다.
prompt = f"""
proofread and correct this review. Make it more compelling.
Ensure it follows APA style guide and targets an advanced reader.
Output in markdown format.
Text: ```{text}```
"""
response = get_completion(prompt)
display(Markdown(response))이번에는 동일하게 리뷰 교정을 요청하고 APA 스타일(학술 논문 작성 시 사용하는 스타일)로 작성하라고 요청하였습니다. 그리고 출력은 마크다운 형식으로 하라고 요청하였습니다.
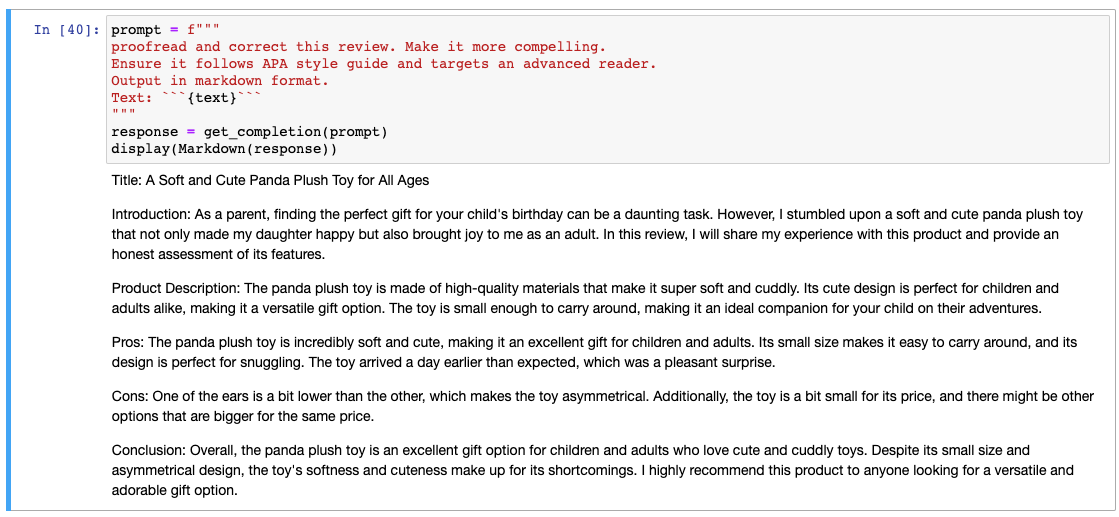
아주 짧은 시간에 다양한 형태로 텍스트를 변환하는 모습을 보았습니다.
다음 강의는 프롬프트를 짧은 텍스트에서 긴 텍스트로 확장하는 방법(이메일, 에세이 등 형태로)에 대해 알아보겠습니다.
7장: Expanding
확장은 짧은 텍스트 조각을 가져오는 작업입니다. 짧은 텍스트를 가져와서 LLM이 이메일이나, 특정 주제에 대한 에세이와 같은 긴 텍스트를 생성하도록 하는 작업입니다. 예를 들어 브레인 스토밍을 할 때와 같이 이 기능을 유용하게 사용할 경우가 많습니다.
하지만 누군가 이 기능을 사용하여 대량의 스팸을 생성하는 것처럼 문제가 있는 사례도 있습니다. 따라서 LLM의 이러한 기능을 사용할 때는 책임감 있는 방식으로 사용해야 합니다.
여기서는 LLM을 사용하여 몇가지 정보를 기반으로 하여 개인화된 이메일을 생성하는 예시를 살펴보겠습니다.
이메일 생성
sentiment = "negative"
# 블렌더에 대한 리뷰
review = f"""
So, they still had the 17 piece system on seasonal \
sale for around $49 in the month of November, about \
half off, but for some reason (call it price gouging) \
around the second week of December the prices all went \
up to about anywhere from between $70-$89 for the same \
system. And the 11 piece system went up around $10 or \
so in price also from the earlier sale price of $29. \
So it looks okay, but if you look at the base, the part \
where the blade locks into place doesn’t look as good \
as in previous editions from a few years ago, but I \
plan to be very gentle with it (example, I crush \
very hard items like beans, ice, rice, etc. in the \
blender first then pulverize them in the serving size \
I want in the blender then switch to the whipping \
blade for a finer flour, and use the cross cutting blade \
first when making smoothies, then use the flat blade \
if I need them finer/less pulpy). Special tip when making \
smoothies, finely cut and freeze the fruits and \
vegetables (if using spinach-lightly stew soften the \
spinach then freeze until ready for use-and if making \
sorbet, use a small to medium sized food processor) \
that you plan to use that way you can avoid adding so \
much ice if at all-when making your smoothie. \
After about a year, the motor was making a funny noise. \
I called customer service but the warranty expired \
already, so I had to buy another one. FYI: The overall \
quality has gone done in these types of products, so \
they are kind of counting on brand recognition and \
consumer loyalty to maintain sales. Got it in about \
two days.
"""위 텍스트는 블렌더 상품에 대한 리뷰입니다. 모델에게 AI 어시스턴트 역할을 부여하여 이 리뷰에 대한 답장을 작성하도록 하겠습니다.
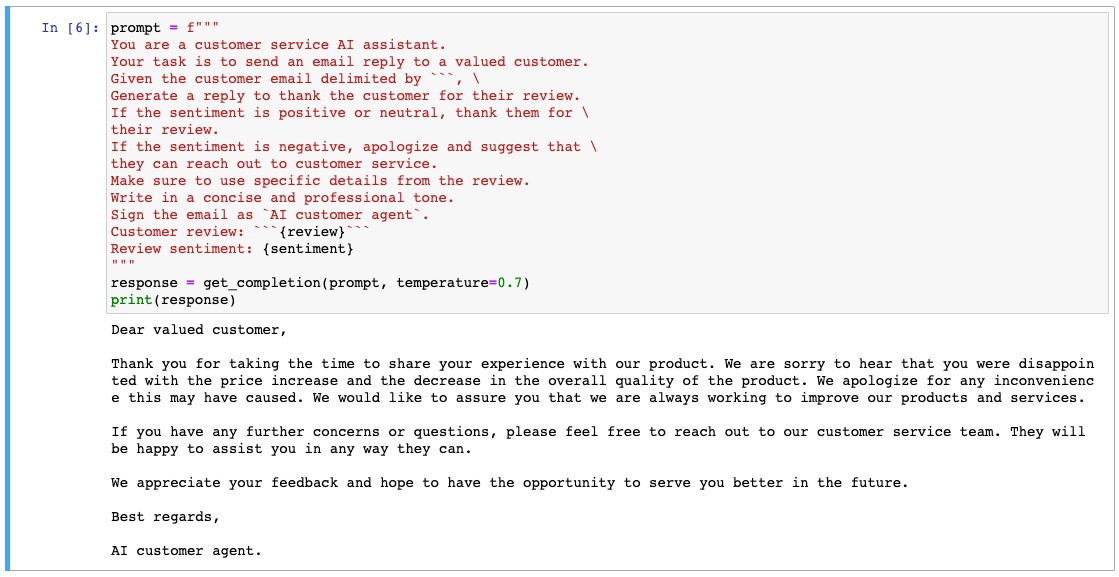
prompt = f"""
You are a customer service AI assistant.
Your task is to send an email reply to a valued customer.
Given the customer email delimited by ```, \
Generate a reply to thank the customer for their review.
If the sentiment is positive or neutral, thank them for \
their review.
If the sentiment is negative, apologize and suggest that \
they can reach out to customer service.
Make sure to use specific details from the review.
Write in a concise and professional tone.
Sign the email as `AI customer agent`.
Customer review: ```{review}```
Review sentiment: {sentiment}
"""
response = get_completion(prompt)
print(response)고객 서비스 AI 어시스턴트라는 역할을 부여받아 고객의 리뷰에 답장을 작성하도록 하였습니다. 긍정적이거나 중립적일 경우 감사를 표하고, 부정적인 감정인 경우에는 사과하고 고객 서비스로 연락하도록 안내해라고 작성되어 있습니다. 또한 리뷰의 구체적인 세부 정보를 사용하라고 적혀있고 간결하고 전문적인 어조로 작성해달라고 요청했습니다.
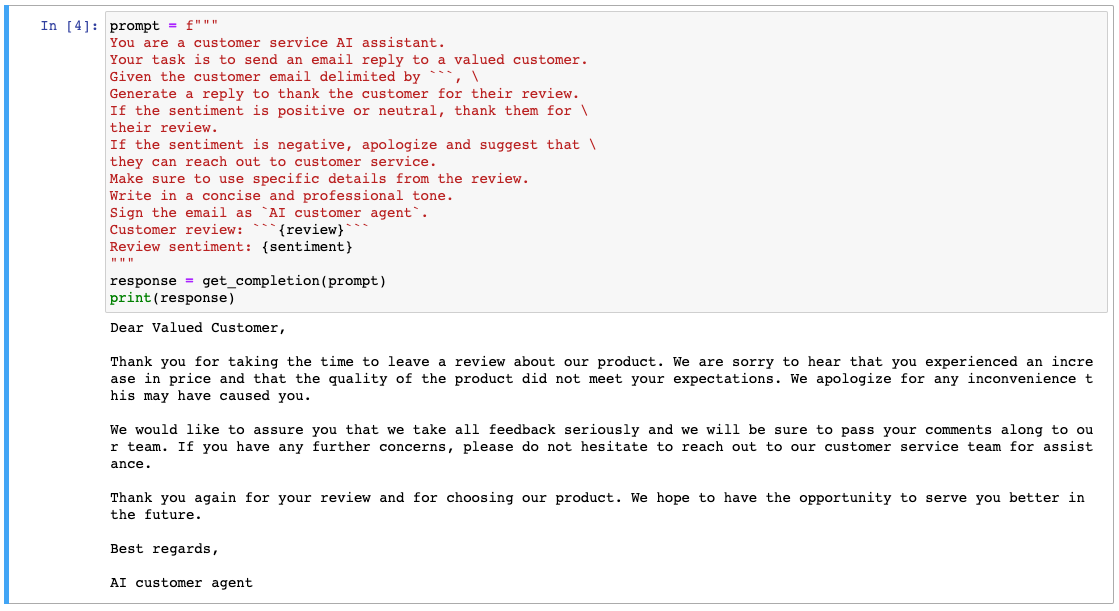
그리고 이 이메일은 AI 봇이 보낸 것으로 서명하라고 요청했고 답변도 그에 따라 작성되어있습니다. 사용자에게 텍스트가 AI에 의해 생성되었다는 사실을 알리는 것은 중요합니다.
리뷰는 앞서 추출한 감정(부정적)을 알고 있습니다. 따라서 우리가 지시한 대로 고객 서비스 센터에 연락하라고 안내하고 있습니다.
Temperature 파라미터
모델에 temperature라는 파라미터를 사용하여 모델 응답의 정도와 다양성을 변화시킬 수 있습니다.
temperature는 모델의 탐색 정도 또는 모델의 무작위성 정도라고 생각하시면 됩니다.
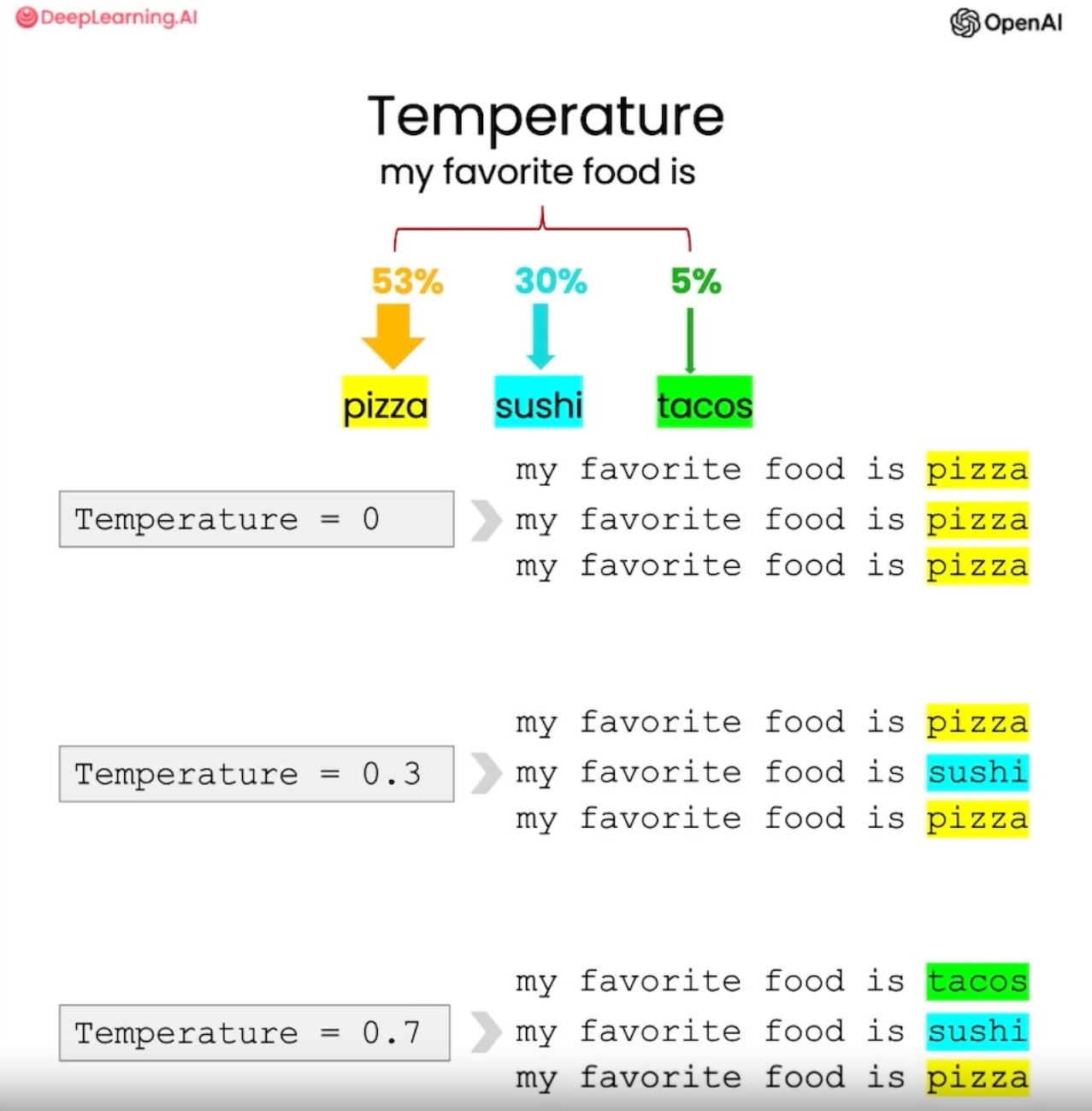
temperature가 낮을수록 모델의 응답은 더 일관적이고 예측 가능하며, 높을수록 더 다양하고 무작위적입니다.
일반적으로 예측 가능한 응답이 필요한 애플리케이션을 구축할 때 temperature 0를 사용하는 것이 좋습니다. 현재 이때까지 강의에 사용된 예시에도 모두 temperature 0으로 사용되었습니다.
prompt = f"""
You are a customer service AI assistant.
Your task is to send an email reply to a valued customer.
Given the customer email delimited by ```, \
Generate a reply to thank the customer for their review.
If the sentiment is positive or neutral, thank them for \
their review.
If the sentiment is negative, apologize and suggest that \
they can reach out to customer service.
Make sure to use specific details from the review.
Write in a concise and professional tone.
Sign the email as `AI customer agent`.
Customer review: ```{review}```
Review sentiment: {sentiment}
"""
response = get_completion(prompt, temperature=0.7)
print(response)temperature=0을 사용하면 매번 동일한 결과를 기대할 수 있습니다.
반면에 temperature=0.7 파라미터를 사용하면 모델의 응답이 더 다양해집니다.
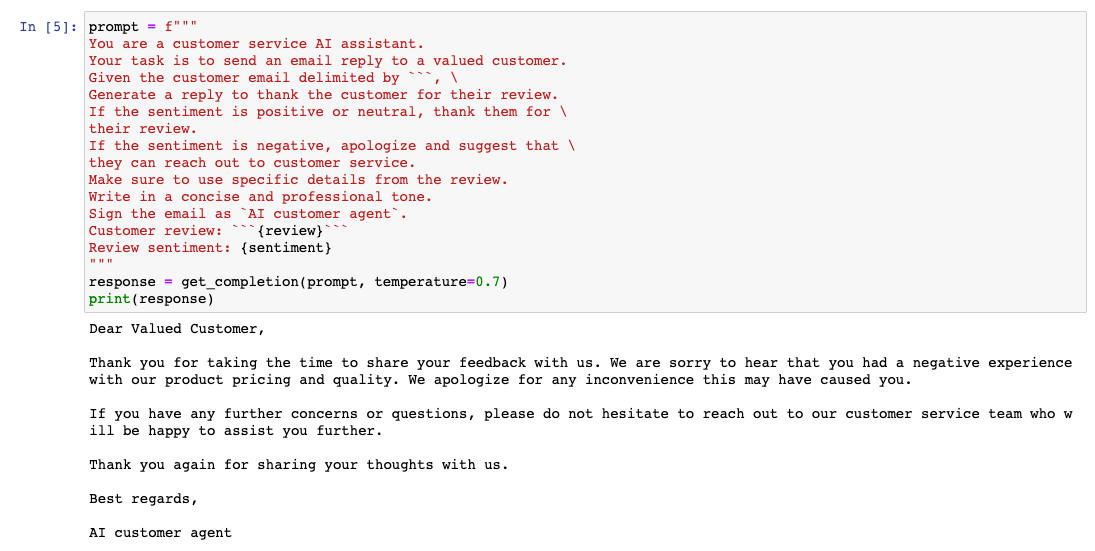
요약하자면, 더 높은 temperature에서는 모델의 출력이 좀 더 무작위적입니다. temperature가 높을 수록 어시스턴트가 더 산만해진다고 생각하시면 됩니다. 그렇지만 더 창의적이라고 생각할 수도 있습니다.
다음 강의에서는 Chat 완료 엔드포인트 타입과 이 타입을 사용하여 커스텀 Chatbot을 만드는 방법을 알아보겠습니다.
8장: Chatbot
LLM의 흥미로운 점 중 하나는 모델을 사용하여 커스텀 Chatbot을 만들 수 있다는 점입니다.
웹 인터페이스인 ChatGPT는 대화형 인터페이스를 구축하여 만든 서비스입니다.
이러한 기능을 사용하여 AI의 역할을 수행할 수 있다는 것입니다. 고객 서비스 상담원, 레스토랑 주문 접수원 등 역할을 수행할 수도 있습니다.
그 방법을 직접 배워보겠습니다.
Chatbot
ChatGPT와 같은 채팅 모델은 실제로 메시지를 입력으로 받아 모델에서 생성된 메시지를 출력으로 반환하도록 학습됩니다. 그리고 여러 차례에 걸친 대화를 쉽게 만들 수 있도록 설계되었지만, 대화가 없는 단일 작업에도 유용하다는 것을 이전 강의에서 확인했습니다.
여기 2개 헬퍼 함수를 정의해보겠습니다.
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
)
return response.choices[0].message["content"]
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # this is the degree of randomness of the model's output
)
# print(str(response.choices[0].message))
return response.choices[0].message["content"]이전 강의에서 계속 사용해온 get_completion 함수와 비슷한 get_completion_from_messages 함수를 만들었습니다.
다른점은 기존 함수에서는 role을 user로 명시 후 사용했지만, 이번에는 함수에서 role을 명시하지 않고
role과 함께 메시지를 명시한 messages를 인자로 받아 사용합니다.
이제 이 함수를 사용하여 예제와 함꼐 살펴보겠습니다.
messages = [
{'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'},
{'role':'user', 'content':'tell me a joke'},
{'role':'assistant', 'content':'Why did the chicken cross the road'},
{'role':'user', 'content':'I don\'t know'} ]위 메시지에서 첫 번째는 전반적인 지침을 제공하는 시스템 메시지고, 두 번째 메시지부터는 사용자와 어시스턴트의 대화가 이어집니다. ChatGPT를 사용해 본 적이 있다면 사용자 메시지는 우리가 작성하는 내용이고 시스템 메시지가 ChatGPT 입니다. 시스템 메시지는 어시스턴트의 행동과 페르소나를 설정하는데 도움이 되며, 대화에 대한 일종의 높은 수준의 지침 역할을 합니다. ChatGPT를 사용해 본 사용자라면 ChatGPT의 시스템 메시지에 어떤 내용이 담겨 있는지 모를 것이고, 이것이 바로 그 의도입니다.

시스템 메시지의 장점은 개발자가 요청 자체를 대화의 일부로 만들지 않고도 대화의 틀을 잡을 수 있는 방법을 제공할 수 있다는 점입니다. 따라서 어시스턴트를 안내하고 귀에 속삭이면서 사용자가 인지하지 못하도록 응답을 유도할 수 있습니다.
새로 작성한 get_completion_from_messages 함수를 이용하여 응답을 확인해보겠습니다.
response = get_completion_from_messages(messages, temperature=1)
print(response)
시스템 메시지로 셰익스피어 어시스턴트를 설정했기 때문에 어시스턴트의 응답이 셰익스피어 스타일로 나옵니다.
또한 매번 다양한 응답을 얻기 위해 temperature=1을 선택했습니다.
농담 하나를 말해달라고 하니 서양 고전 농담 중 하나인 닭이 길을 건너간 이유에 대한 셰익스피어식 답변을 얻었습니다.
또 다른 예시를 보겠습니다.
messages = [
{'role':'system', 'content':'You are friendly chatbot.'},
{'role':'user', 'content':'Hi, my name is Isa'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)시스템 메시지로 친구처럼 대화하는 챗봇을 설정했기 때문에 친구처럼 대화하는 챗봇이 응답합니다.

그럼 다음에 아래와 같은 메시지를 보내면 어떻게 될까요?
messages = [
{'role':'system', 'content':'You are friendly chatbot.'},
{'role':'user', 'content':'Yes, can you remind me, What is my name?'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)
모델은 실제로 사용자의 이름을 알지 못합니다. 모델과의 각 대화는 독립적인 상호 작용이므로 모델이 참고할 수 있는 모든 관련 메시지를 제공해야 합니다.
messages = [
{'role':'system', 'content':'You are friendly chatbot.'},
{'role':'user', 'content':'Hi, my name is Isa'},
{'role':'assistant', 'content': "Hi Isa! It's nice to meet you. \
Is there anything I can help you with today?"},
{'role':'user', 'content':'Yes, you can remind me, What is my name?'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)
이제 모델은 사용자의 이름을 알고 있으므로 사용자의 이름을 알고 있다고 답변합니다.

위 처럼 제공된 이전 대화를 컨텍스트라고 합니다. 모델이 필요한 컨텍스트를 갖고 있기 때문에 모델은 사용자의 이름을 응답할 수 있습니다.
커스텀 Chatbot: 주문bot
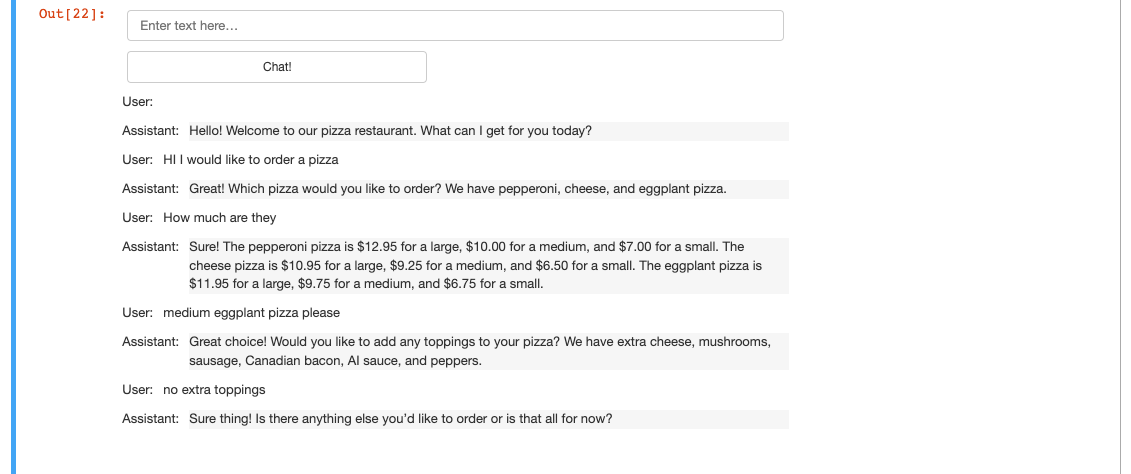
이제 커스텀 Chatbot을 만들어 보겠습니다.
사용자 프롬프트, 어시스턴트 응답 수집을 자동화하여 피자가게 주문bot을 만들어보겠습니다.
def collect_messages(_):
prompt = inp.value_input
inp.value = ''
context.append({'role':'user', 'content':f"{prompt}"})
response = get_completion_from_messages(context)
context.append({'role':'assistant', 'content':f"{response}"})
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)우선 사용자 프롬프트, 어시스턴트 응답 수집을 자동화하는 collect_messages 함수를 작성합니다.
위에서 했던 방식으로 사용자 메시지를 수집하고 컨텍스트라는 목록을 추가하여 매번 해당 컨텍스트를 사용하여
모델을 호출합니다.
import panel as pn # GUI
pn.extension()
panels = [] # collect display
context = [ {'role':'system', 'content':"""
You are OrderBot, an automated service to collect orders for a pizza restaurant. \
You first greet the customer, then collects the order, \
and then asks if it's a pickup or delivery. \
You wait to collect the entire order, then summarize it and check for a final \
time if the customer wants to add anything else. \
If it's a delivery, you ask for an address. \
Finally you collect the payment.\
Make sure to clarify all options, extras and sizes to uniquely \
identify the item from the menu.\
You respond in a short, very conversational friendly style. \
The menu includes \
pepperoni pizza 12.95, 10.00, 7.00 \
cheese pizza 10.95, 9.25, 6.50 \
eggplant pizza 11.95, 9.75, 6.75 \
fries 4.50, 3.50 \
greek salad 7.25 \
Toppings: \
extra cheese 2.00, \
mushrooms 1.50 \
sausage 3.00 \
canadian bacon 3.50 \
AI sauce 1.50 \
peppers 1.00 \
Drinks: \
coke 3.00, 2.00, 1.00 \
sprite 3.00, 2.00, 1.00 \
bottled water 5.00 \
"""} ] # accumulate messages
inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…')
button_conversation = pn.widgets.Button(name="Chat!")
interactive_conversation = pn.bind(collect_messages, button_conversation)
dashboard = pn.Column(
inp,
pn.Row(button_conversation),
pn.panel(interactive_conversation, loading_indicator=True, height=300),
)
dashboard시스템 메시지에 어떤 것을 넣었는지 살펴보겠습니다.
우선 피자 주문을 받는 주문 봇입니다.
시작할 때 먼저 고객에게 인사를 건네고 주문을 받으세요.
픽업인지 배달인지 물어보고 그 후 전체 주문을 받을 때까지 기다립니다.
전체 주문 내용을 요약하고 마지막으로 더 추가할 것이 있는지 확인합니다.
배송인 경우엔 추가로 주소를 묻습니다.
마지막으로 결제 금액을 받습니다.
모든 옵션, 크기를 명확히 하고 고객이 주문을 쉽게 할 수 있도록 응답합니다.
응답은 짧고 대화하듯 친근한 스타일로 하도록 합니다.
(메뉴...)이제 피자 주문bot을 대시보드를 만듭니다.
여기서는 panel 라이브러리를 사용합니다.
대화를 컨텍스트에 계속 추가하여 제공하기에 컨텍스트는 점점 더 길어집니다.
그리고 이 결과를 시스템에서 사용할 수 있도록 JSON 형식으로 요약하기 위해 모델에 요청할 수 있습니다.
messages = context.copy()
messages.append(
{'role':'system', 'content':'create a json summary of the previous food order. Itemize the price for each item\
The fields should be 1) pizza, include size 2) list of toppings 3) list of drinks, include size 4) list of sides include size 5)total price '},
)
#The fields should be 1) pizza, price 2) list of toppings 3) list of drinks, include size include price 4) list of sides include size include price, 5)total price '},
response = get_completion_from_messages(messages, temperature=0)
print(response)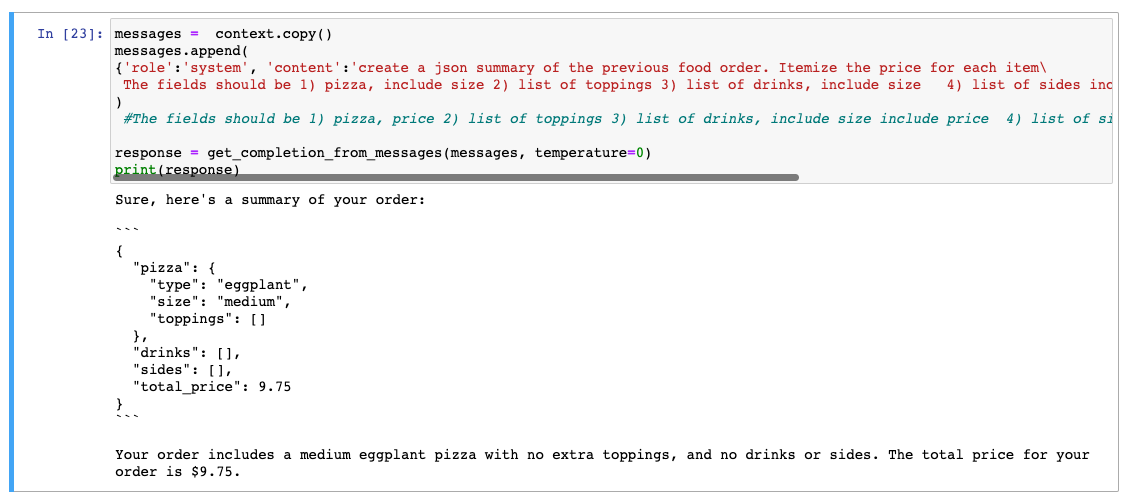
이제 나만의 주문bot을 만들었습니다.
위 경우에는 더 낮은 temperature를 사용하고 있습니다.
결과를 예측할 수 있어야 하기 때문입니다. 대화형 에이전트의 경우 더 높은 temperature를 사용할 수도 있습니다.
고객 도우미 Chatbot의 경우 좀 더 에측 가능한 결과를 원할 것입니다.
자유롭게 커스터마이징한 시스템 메시지를 사용하여 Chatbot의 동작을 변경하고 다른 페르소나처럼 행동하도록 할 수 있습니다.
9장: Conclusion
이 단기 강의 과정에서 다음과 같은 두 가지 핵심 원칙을 배웠습니다.
- 명확하고 구체적인 지침을 작성하기
- 모델에게 생각할 시간주기
또한 반복적인 프롬프트 개발과 애플리케이션에 적합한 프롬프트에 도달하기 위한 프로세스를 갖추는 것이 얼마나 중요한지 배웠습니다.
그리고 많은 애플리케이션에 유용한 LLM의 몇 가지 기능도 살펴보았습니다. 특히, Summarizing, Inferring, Transforming, Expanding에 대해 살펴보았습니다.
마지막으로는 커스텀 Chatbot을 만드는 방법도 살펴보았습니다. 단 한 번의 짧은 강좌로 많은 것을 배웠습니다.
이제 직접 아이디어를 떠올려서 만들어보시길 바랍니다. 아주 작은 프로젝트부터 시작해도 괜찮습니다. 재밌는 것 부터 시작해보세요.
그리고 아시다시피 다시 한 번 말씀드리지만, 이러한 종류의 LLM은 매우 강력한 기술이기 때문에 책임감 있게 사용해 주실 것을 부탁드리며 긍정적인 영향을 미칠 수 있는 것만 만들어 주시기 바랍니다.
마무리하며
강의가 전체 1시간 가량으로 짧은 강의였지만 많은 것을 배울 수 있었습니다. (사실 저는 엄청 더 걸렸습니다. 😅)
무엇보다 좋았던 것은 제공된 파이썬 코드가 강의 영상 옆에서 바로 실행되어 결과를 확인할 수 있었던 것이었습니다. 직접 실습도 해보고 여러가지 변형도 하면서 재밌게 강의를 들었습니다.
프롬프트 엔지니어링이 요즘 이슈가 되고 많은 것을 대체할 것처럼 과대프로모션을 해서 이 강의를 들어보았습니다.
LLM이 정말 마법(마술)처럼 보이도록 해주는 것이 사실인 것 같습니다. 개발할 때에도 ChatGPT를 모니터 한 곳에 띄어두고 작업을 하기도 했지만 그래도 놀랍습니다.
이 강의를 들으면서 느낀 것은 LLM이 정말 강력한 기술이라는 것과 이 기술을 적절하게 사용하면 정말 많은 것을 할 수 있다는 것입니다. 그리고 이 기술을 사용하는 것은 정말 쉽습니다.
저는 이 프롬프트 엔지니어링이 앞으로 애플리케이션 개발에 많은 도움이 될 것이라고 생각합니다. 앞으로의 개발 방향이 이와 비슷한 방향으로 가게 되지 않을까 하는 생각도 하게 됩니다.
앞으로 항상 시야에 두고 관심있게 지켜보려고 합니다.
사용된 파이썬 예제 코드는 강의마다 제공되지만 제가 실습해본 코드에서도 확인할 수 있습니다.
reference
마지막 업데이트
5/5/2023
